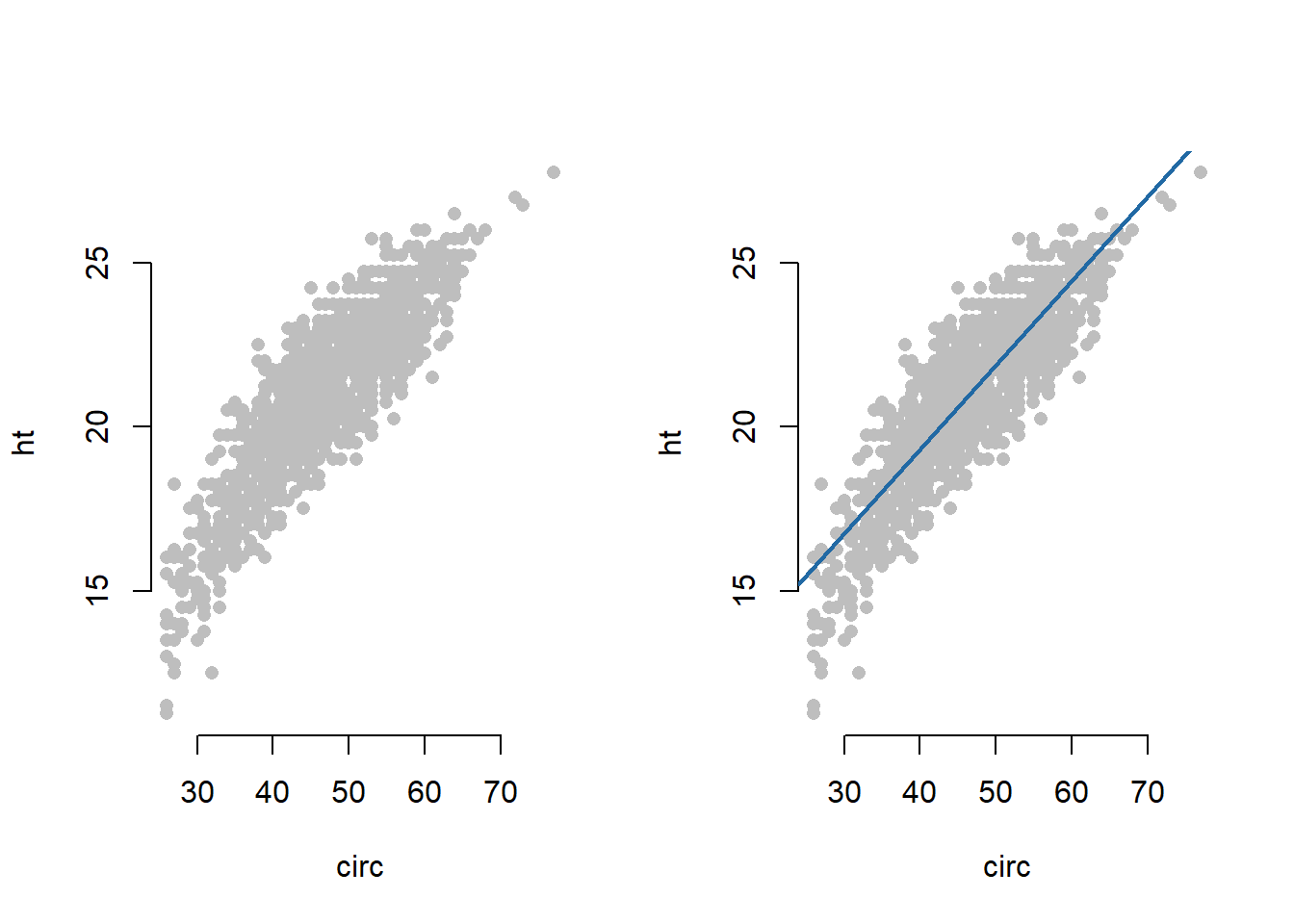
circ și ht împreună cu dreapta de regresie.
Curs 2 - Regresie liniară simplă (I)
În cele ce urmează vom considera cazul modelului de regresie liniară simplă
\[ y = \beta_0 + \beta_1 x + \varepsilon, \]
unde, în forma generală \(y = f(x) + \varepsilon\), media condiționată (componenta sistematică) \(\mathbb{E}[y|x] = f(x)\) este presupusă liniară. Specific, pentru un eșantion de \(n\) puncte \((x_i, y_i)\) modelul de regresie liniară simplă se scrie sub forma
\[ y_i = \beta_0 + \beta_1 x_{i} + \varepsilon_i, \quad i = 1,\ldots,n. \]
Modelul clasic de regresie presupune că termenii eroare sunt variabile aleatoare necorelate, centrate și de varianță constantă (homoscedasticitate), altfel spus aceștia îndeplinesc ipotezele:
\[ (\mathcal{H})\left\{\begin{array}{l} \left(\mathcal{H}_{1}\right): \mathbb{E}\left[\varepsilon_{i}\right]=0 \text { pentru toți indicii } i \\ \left(\mathcal{H}_{2}\right): \operatorname{Cov}\left(\varepsilon_{i}, \varepsilon_{j}\right)=\delta_{i j} \sigma^{2} \text { pentru toate perechile }(i, j) \end{array}\right. \]
unde \(\delta_{ij} = 1\) dacă \(i = j\) și \(\delta_{ij} = 0\) altfel.
Pentru a determina coeficienții de regresie (\(\beta_0\) și \(\beta_1\)) vom folosi ca funcție de pierdere, costul pătratic \(L(u) = u^2\).
În acest context, numim estimatori obținuți prin metoda celor mai mici pătrate (OLS - Ordinary Least Squares) valorile \(\hat{\beta}_0\) și \(\hat{\beta}_1\) care minimizează funcția (\(RSS\) - Residual Sum of Squares)
\[ RSS(\beta_0, \beta_1) = \sum_{i = 1}^{n}(y_i - \beta_0 - \beta_1 x_i)^2 \]
altfel spus, dreapta de regresie obținută prin metoda celor mai mici pătrate minimizează distanțele verticale dintre punctele \((x_i,y_i)\) și dreapta ajustată \(y = \hat{\beta}_0 + \hat{\beta}_1 x\). Pentru unicitatea estimatorilor \(\hat{\beta}_0\) și \(\hat{\beta}_1\) vom presupune că setul de date conține cel puțin două puncte de abscise diferite, i.e. \(x_i\neq x_j\).
Exemplul 1.1 (Înălțimea arborilor de eucalipt) Ca prim exemplu, putem considera setul de date referitor la înălțimea și circumferința arborilor de eucalipt. Modelul de regresie liniară simplă prin care dorim să explicăm înălțimea (medie) a arborilor (variabila răspuns) în funcție de circumferința lor (variabila explicativă) este dat de
\[ ht_i = \beta_0 + \beta_1 circ_i + \varepsilon_i, \quad i =1,\ldots, 1429. \]
circ și ht împreună cu dreapta de regresie.
Exemplul 1.2 (Prețul chiriilor în Munchen) Să considerăm acum setul de date referitor la prețul chiriilor în Munchen pentru apartamentele dintr-o locație medie, construite după anul 1966. Diagrama de împrăștiere ilustrată în figura de mai jos, prezintă o relație aproximativ liniară între prețul net al chiriei (variabila răspuns) și suprafață (covariabila).
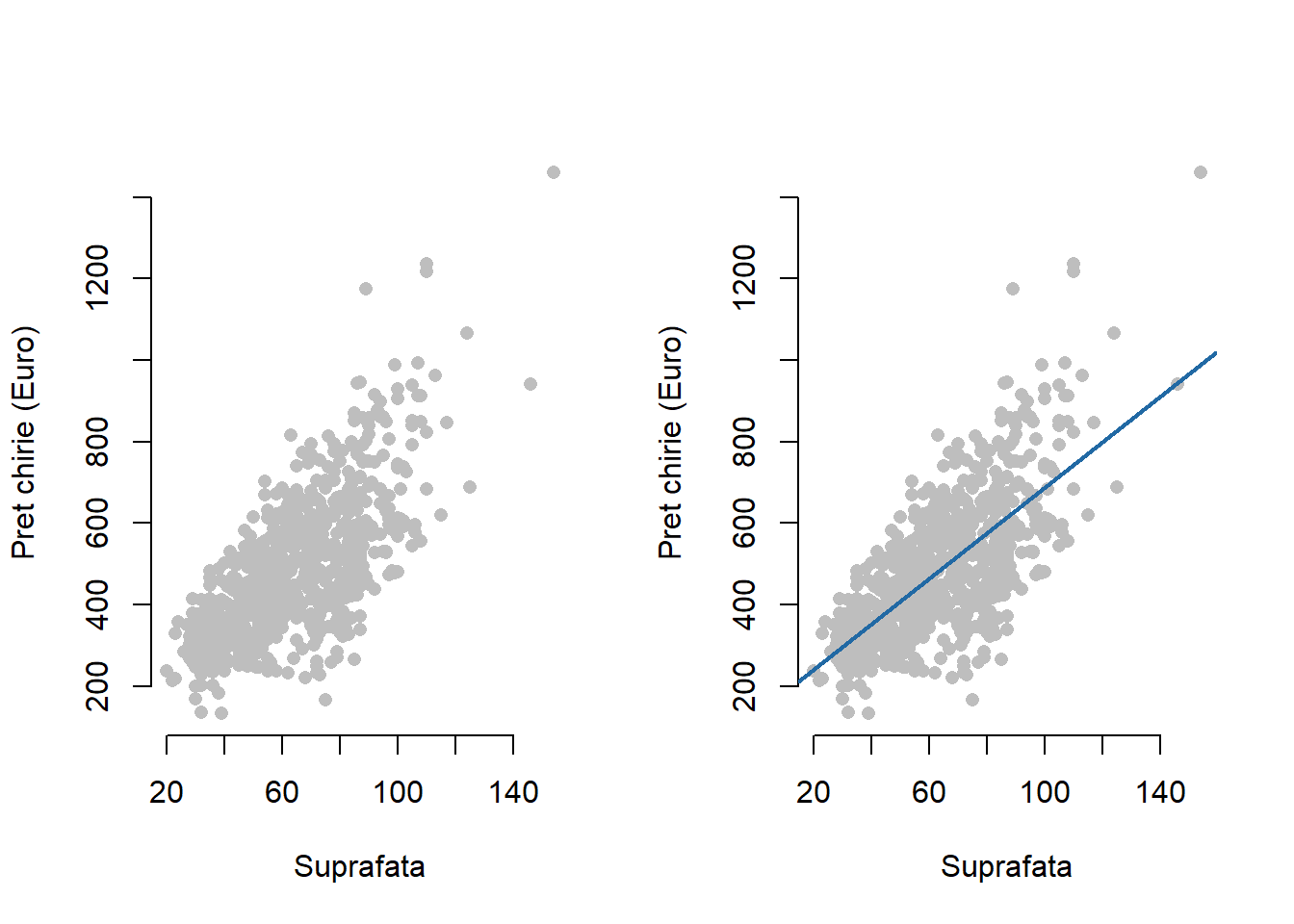
Modelul de regresie liniară simplă se scrie
\[ pret_i = \beta_0 + \beta_1 suprafata_i + \varepsilon_i \]
ceea ce înseamnă că prețul de închiriere mediu este o funcție liniară de suprafața de locuit, i.e. \(\mathbb{E}[pret|suprafata] = \beta_0 + \beta_1 suprafata\).
Metoda celor mai mici pătrate este o metodă deterministă de calcul a estimatorilor coeficienților dreptei de regresie, ipotezele făcute asupra termenilor eroare nu intervin în acest calcul. Acestea din urmă vor interveni atunci când vrem să explicităm proprietățile statistice ale acestor estimatori.
Propoziția 2.1 (Estimatorii obținuți prin metode celor mai mici pătrate) Estimatorii \(\hat{\beta}_0\) și \(\hat{\beta}_1\) obținuți prin metoda celor mai mici pătrate, adică valorile coeficienților \(\beta_0\) și \(\beta_1\) care minimizează funcția
\[ RSS(\beta_0, \beta_1) = \sum_{i = 1}^{n}(y_i - \beta_0 - \beta_1 x_i)^2 \]
sunt dați de expresiile
\[ \hat\beta_0 = \bar y - \hat\beta_1 \bar x \quad \text{și} \quad \hat\beta_1 = \frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}. \]
Demonstrație (Propoziția 2.1). Trebuie să determinăm
\[ (\hat{\beta}_0, \hat{\beta}_1) = \underset{(\beta_0,\beta_1)\in\mathbb{R}\times\mathbb{R}}{\arg\min} RSS(\beta_0, \beta_1) \]
și observând că funcția \(RSS(\beta_0, \beta_1)\) este convexă ea admite un punct de minim. Acesta se obține ca soluție a sistemului \(\nabla RSS = 0\) de ecuații normale,
\[ \left\{\begin{array}{ll} \frac{\partial RSS}{\partial \beta_0} = -2\sum_{i = 1}^{n}(y_i - \beta_0 - \beta_1 x_i) = 0\\ \frac{\partial RSS}{\partial \beta_1} = -2\sum_{i = 1}^{n}x_i(y_i - \beta_0 - \beta_1 x_i) = 0 \end{array}\right. \]
Din prima ecuație obținem prin sumare \(n\beta_0 + \beta_1\sum_{i=1}^{n}x_i = \sum_{i=1}^{n}y_i\) ceea ce conduce la \(\hat\beta_0 = \bar y - \hat\beta_1 \bar x\).
A doua ecuație conduce la
\[ \beta_0\sum_{i=1}^{n}x_i + \beta_1\sum_{i=1}^{n}x_i^2 = \sum_{i=1}^{n}x_iy_i \]
și înlocuind \(\beta_0\) cu expresia obținută anterior, obținem soluția
\[ \hat\beta_1 = \frac{\sum_{i = 1}^{n}x_i(y_i - \bar y)}{\sum_{i = 1}^{n}x_i(x_i - \bar x)} = \frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2} = \frac{\sum_{i = 1}^{n}(x_i - \bar x)y_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2}. \]
De asemenea, se poate verifica că \(RSS(\beta_0, \beta_1)\) se scrie sub forma
\[\begin{align*} RSS(\beta_0, \beta_1) &= n\left[\beta_0 - (\bar y - \beta_1\bar x)\right]^2 + \left[\sum_{i = 1}^{n}(x_i - \bar x)^2\right]\left[\beta_1 - \frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\right]^2 \\ &\quad + \left[\sum_{i = 1}^{n}(y_i - \bar y)^2\right]\left[1 - \frac{\left(\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)\right)^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2\sum_{i = 1}^{n}(y_i - \bar y)^2}\right] \end{align*}\]care justifică în egală măsură soluția obținută anterior.
Odată ce am determinat estimatorii \(\hat{\beta}_0\) și \(\hat{\beta}_1\) putem scrie dreapta de regresie sub forma
\[ \hat y = \hat \beta_0 + \hat\beta_1 x, \]
și, în acest context, dacă evaluăm dreapta în punctele \(x_i\) care au ajutat la estimarea parametrilor atunci obținem valorile ajustate (fitate) \(\hat y_i\) iar dacă evaluăm dreapta în alte puncte, valorile obținute se numesc valori prezise (valori previzionale). De asemenea, din \(\hat\beta_0 = \bar y - \hat\beta_1 \bar x\) se remarcă faptul că dreapta de regresie trece prin punctul de coordonate \((\bar x, \bar y)\), centrul de greutate al norului de puncte.
Exemplul 2.1 (Prețul chiriilor în Munchen) Putem ilustra modelul de regresie liniară simplă în contextul prețului chiriilor din Munchen pentru apartamentele construite după anul 1966 care se regăsesc într-o locție medie. Conform metodei celor mai mici pătrate, găsim că \(\hat{\beta}_0=\) 130.554 și respectiv \(\hat{\beta}_1=\) 5.576 ceea ce conduce la modelul
\[ pret_i = 130.554 + 5.576 suprafata_i + \varepsilon_i. \]
Panta dreptei de regresie, coeficientul \(\hat{\beta}_1=\) 5.576 poate fi interpretat în modul următor: dacă suprafața de locuit crește cu \(1\) \(m^2\) atunci prețul chiriei crește în medie cu 5.576 Euro.
Sub ipotezele făcute asupra termenilor eroare (\(\mathcal{H}_1\) și \(\mathcal{H}_2\)), de centrare, necorelare și homoscedasticitate putem prezenta o serie de proprietăți ale estimatorilor obținuți prin metoda celor mai mici pătrate.
Propoziția 2.2 (Proprietatea de nedeplasare) Estimatorii obținuți prin metoda celor mai mici pătrate, \(\hat\beta_0\) și \(\hat\beta_1\), sunt estimatori nedeplasați.
Demonstrație (Propoziția 2.2). Coeficienții \(\hat\beta_0\) și \(\hat\beta_1\) obținuți prin metoda celor mai mici pătrate sunt dați de \(\hat\beta_0 = \bar y - \hat\beta_1 \bar x\) și \(\hat\beta_1 = \frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\) (aceștia sunt variabile aleatoare deoarece sunt funcții de \(Y_i\) care sunt variabile aleatoare). Înlocuind în expresia lui \(\hat\beta_1\) pe \(y_i\) cu \(\beta_0+\beta_1 x_i + \varepsilon_i\) avem
\[\begin{align*} \hat\beta_1 &= \frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2} = \frac{\sum_{i = 1}^{n}(x_i - \bar x)y_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2} = \frac{\sum_{i = 1}^{n}(x_i - \bar x)(\beta_0+\beta_1 x_i + \varepsilon_i)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\\ &= \frac{\beta_0\overbrace{\sum_{i = 1}^{n}(x_i - \bar x)}^{ = 0} + \beta_1 \sum_{i = 1}^{n}(x_i - \bar x)x_i + \sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2} \\ &= \frac{\beta_1 \sum_{i = 1}^{n}(x_i - \bar x)^2 + \sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\\ &= \beta_1 + \frac{\sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2}. \end{align*}\]Conform ipotezei modelului de regresie liniară simplă, \(\mathbb{E}[\varepsilon_i] = 0\), prin urmare \(\mathbb{E}[\hat\beta_1] = \beta_1\) ceea ce arată că \(\hat\beta_1\) este un estimator nedeplasat pentru \(\beta_1\).
În mod similar,
\[ \mathbb{E}[\hat\beta_0] = \mathbb{E}[\bar y] - \bar x\mathbb{E}[\hat\beta_1] = \beta_0 + \bar x\beta_1 - \bar x\beta_1 = \beta_0 \]
ceea ce arată că \(\hat\beta_0\) este un estimator nedeplasat pentru \(\beta_0\).
Putem de asemenea să determinăm varianța și covarianța estimatorilor \(\hat\beta_0\) și \(\hat\beta_1\).
Propoziția 2.3 (Matricea de varianță-covarianță) Matricea de varianță-covarianță a estimatorilor \(\hat\beta_0\) și \(\hat\beta_1\) este
\[ \begin{pmatrix}Var(\hat \beta_0) & Cov(\hat \beta_0, \hat \beta_1)\\ Cov(\hat \beta_0, \hat \beta_1) & Var(\hat \beta_1)\end{pmatrix} = \begin{pmatrix}\frac{\sigma^2\sum_{i = 1}^{n}x_i^2}{n\sum_{i = 1}^{n}(x_i - \bar x)^2} & -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\\ -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2} & \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\end{pmatrix}. \]
Demonstrație (Propoziția 2.3). Notăm cu \(W = \begin{pmatrix}Var(\hat \beta_0) & Cov(\hat \beta_0, \hat \beta_1)\\ Cov(\hat \beta_0, \hat \beta_1) & Var(\hat \beta_1)\end{pmatrix}\) matricea de varianță-covarianță a estimatorilor \(\hat\beta_0\) și \(\hat\beta_1\).
Avem, folosind expresia lui \(\hat\beta_1\) determinată la punctul anterior și homoscedasticitatea și necorelarea erorilor \(Cov(\varepsilon_i, \varepsilon_j) = \delta_{ij}\sigma^2\), că
\[\begin{align*} Var(\hat \beta_1) &= Var\left(\beta_1 + \frac{\sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\right) = Var\left(\frac{\sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\right)\\ &= \frac{Var\left(\sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i\right)}{\left[\sum_{i = 1}^{n}(x_i - \bar x)^2\right]^2} = \frac{\sum_{i,j}(x_i - \bar x)(x_j - \bar x)Cov(\varepsilon_i, \varepsilon_j)}{\left[\sum_{i = 1}^{n}(x_i - \bar x)^2\right]^2}\\ &= \frac{\sum_{i = 1}^{n}(x_i - \bar x)^2\sigma^2}{\left[\sum_{i = 1}^{n}(x_i - \bar x)^2\right]^2} = \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}. \end{align*}\]Pentru a determina \(Var(\hat \beta_0)\), vom folosi relația \(\hat \beta_0 = \bar y - \hat \beta_1 \bar x\) ceea ce conduce la
\[\begin{align*} Var(\hat \beta_0) &= Var(\bar y - \hat \beta_1 \bar x) = Var(\bar y) - 2Cov(\bar y, \hat \beta_1 \bar x) + Var(\hat \beta_1 \bar x)\\ &= Var\left(\frac{1}{n}\sum_{i = 1}^{n}y_i\right) - 2\bar x Cov(\bar y, \hat \beta_1) + \bar x^2 Var(\hat \beta_1)\\ &= \frac{\sigma^2}{n} + \bar x^2 \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2} - 2\bar x Cov(\bar y, \hat \beta_1). \end{align*}\]Pentru \(Cov(\bar y, \hat \beta_1)\) avem (ținând cont de faptul că \(\beta_0\), \(\beta_1\) și \(x_i\) sunt constante)
\[ \begin{aligned} Cov(\bar y, \hat \beta_1) &= Cov\left(\frac{1}{n}\sum_{i = 1}^{n}y_i, \beta_1 + \frac{\sum_{j = 1}^{n}(x_j - \bar x)\varepsilon_j}{\sum_{j = 1}^{n}(x_j - \bar x)^2} \right) \\ &= \frac{1}{n}\sum_{i = 1}^{n}Cov\left(\beta_0 + \beta_1 x_i + \varepsilon_i, \beta_1 + \frac{\sum_{j = 1}^{n}(x_j - \bar x)\varepsilon_j}{\sum_{j = 1}^{n}(x_j - \bar x)^2}\right)\\ &= \frac{1}{n}\sum_{i = 1}^{n}Cov\left(\varepsilon_i, \frac{\sum_{j = 1}^{n}(x_j - \bar x)\varepsilon_j}{\sum_{j = 1}^{n}(x_j - \bar x)^2}\right) \\ &= \frac{1}{n}\sum_{i = 1}^{n}\frac{1}{\sum_{j = 1}^{n}(x_j - \bar x)^2}Cov\left(\varepsilon_i, \sum_{j = 1}^{n}(x_j - \bar x)\varepsilon_j\right)\\ &= \frac{1}{\sum_{j = 1}^{n}(x_j - \bar x)^2}\sum_{i = 1}^{n}\frac{1}{n}\sum_{j = 1}^{n}(x_j - \bar x)Cov(\varepsilon_i, \varepsilon_j) \\ &= \frac{1}{\sum_{j = 1}^{n}(x_j - \bar x)^2}\sum_{i = 1}^{n}\frac{1}{n}\sum_{j = 1}^{n}(x_j - \bar x)\delta_{ij}\sigma^2\\ &= \frac{\sigma^2}{\sum_{j = 1}^{n}(x_j - \bar x)^2}\frac{1}{n}\underbrace{\sum_{i = 1}^{n}(x_i - \bar x)}_{=0} = 0 \end{aligned} \]
prin urmare
\[ Var(\hat \beta_0) = \frac{\sigma^2}{n} + \bar x^2 \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2} = \frac{\sigma^2\sum_{i = 1}^{n}x_i^2}{n\sum_{i = 1}^{n}(x_i - \bar x)^2}. \]
Calculul covarianței dintre \(\hat \beta_0\) și \(\hat \beta_1\) rezultă aplicând relațiile de mai sus
\[ Cov(\hat \beta_0, \hat \beta_1) = Cov(\bar y - \hat \beta_1\bar x, \hat \beta_1) = Cov(\bar y, \hat \beta_1) - \bar x Var(\hat \beta_1) = -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2}. \]
Observăm că \(Cov(\hat \beta_0, \hat \beta_1)\leq 0\) iar intuitiv, cum dreapta de regresie (bazată pe estimatorii obținuți prin metoda celor mai mici pătrate) \(\bar y = \hat\beta_0 + \hat\beta_1 \bar x\) trece prin centrul de greutate al datelor \((\bar x, \bar y)\), dacă presupunem \(\bar x > 0\) remarcăm că atunci când creștem panta (creștem \(\hat\beta_1\)) ordonata la origine scade (scade \(\hat\beta_0\)) și reciproc.
Matricea de varianță-covarianță a estimatorilor \(\hat\beta_0\) și \(\hat\beta_1\) devine
\[ W = \begin{pmatrix}Var(\hat \beta_0) & Cov(\hat \beta_0, \hat \beta_1)\\ Cov(\hat \beta_0, \hat \beta_1) & Var(\hat \beta_1)\end{pmatrix} = \begin{pmatrix}\frac{\sigma^2\sum_{i = 1}^{n}x_i^2}{n\sum_{i = 1}^{n}(x_i - \bar x)^2} & -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\\ -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2} & \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\end{pmatrix}. \]
Din expresia \(Var(\hat \beta_1)\) observăm că dacă \(\sigma^2\) este mică (cu alte cuvinte \(y_i\) sunt aproape de dreapta de regresie) atunci estimarea este mai precisă. De asemenea, se constată că pe măsură ce valorile \(x_i\) sunt mai dispersate în jurul valorii medii \(\bar x\) estimarea coeficientului \(\hat \beta_1\) este mai precisă (\(Var(\hat \beta_1)\) este mai mică). Acest fenomen se poate observa și în figura de mai jos în care am generat \(100\) de valori aleatoare \(X\) și \(100\) de valori pentru \(Y\) după modelul
\[ y = 1 + 2 x + \varepsilon \]
cu \(\varepsilon\sim \mathcal{N}(0, \sigma^2)\). Dreapta roșie descrie adevărata relație \(f(x) = 1 + 2x\) în populație iar dreapta albastră reprezintă dreapta de regresie calculată cu ajutorul metodei celor mai mici pătrate (OLS). Dreptele albastru deschis au fost generate tot cu ajutorul metodei celor mai mici pătrate atunci când variem \(\sigma^2\) (în figura din stânga) și respectiv pe \(x_i\) în jurul lui \(\bar x\) (în figura din dreapta).
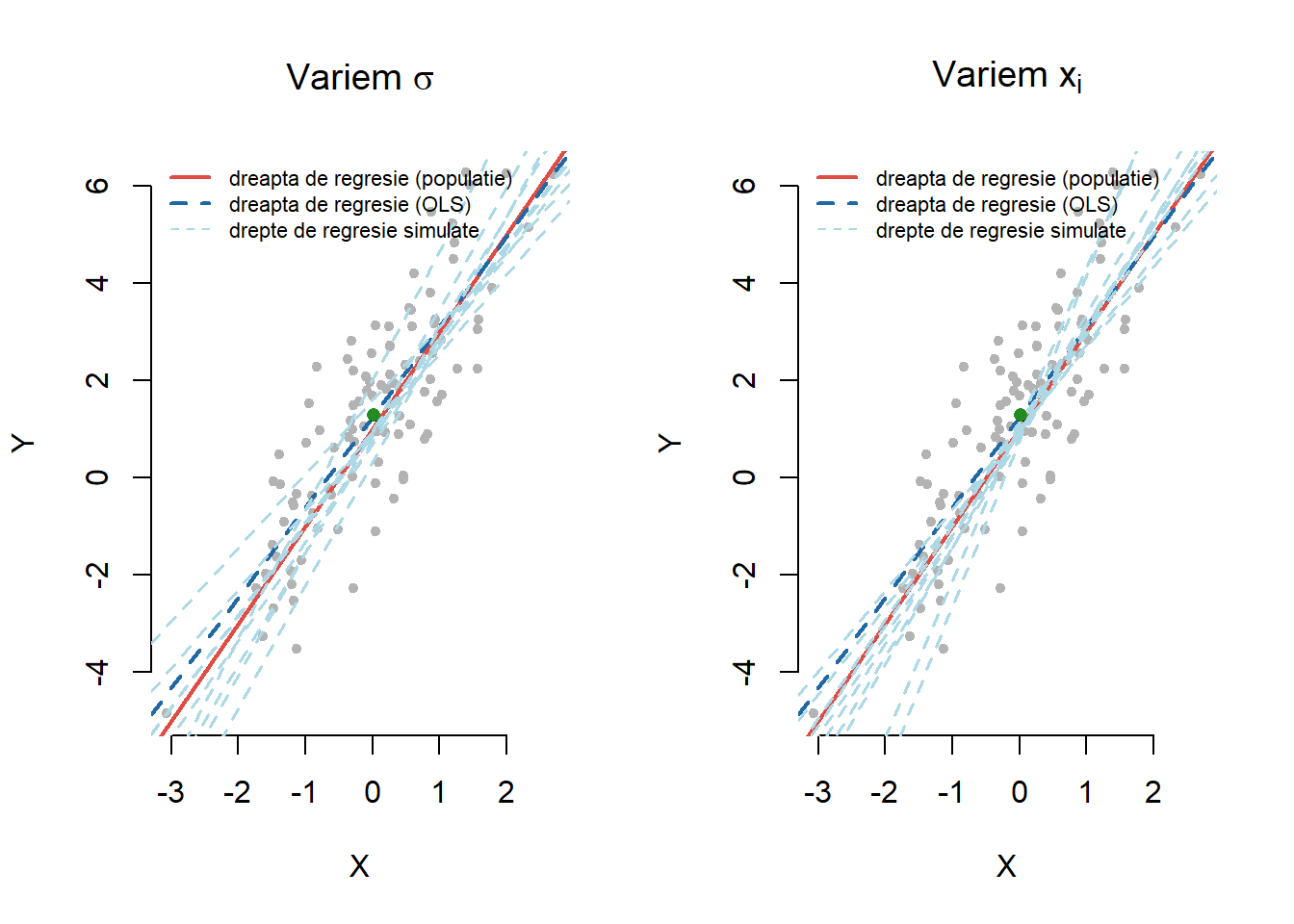
Rezultatul următor, cunoscut și sub numele de Teorema Gauss-Markov, afirmă că estimatorii obținuți prin metoda celor mai mici pătrate sunt optimali în clasa estimatorilor liniari și nedeplasați.
Propoziția 2.4 (Teorema Gauss-Markov) În clasa estimatorilor nedeplasați și liniari în \(y\), estimatorii \(\hat\beta_0\) și \(\hat\beta_1\) sunt de varianță minimală.
Demonstrație (Propoziția 2.4). Începem prin a reaminti că un estimator este liniar în \(y\) dacă se poate scrie sub forma \(\sum_{i=1}^{n}d_i y_i\) cu \(d_1,\ldots,d_n\) constante. Să observăm că atât \(\hat\beta_0\) cât și \(\hat\beta_1\) sunt estimatori liniari în \(y_i\), \(\hat\beta_1 = \sum_{i=1}^{n}\lambda_i y_i\) unde \(\lambda_i = \frac{(x_i - \bar x)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\).
Fie \(\tilde \beta_1\) un alt estimator liniar și nedeplasat pentru \(\beta_1\), cu alte cuvinte
\[ \underbrace{\tilde\beta_1 = \sum_{i=1}^{n}d_i y_i}_{liniaritate} \quad \text{și}\quad \underbrace{\mathbb{E}[\tilde\beta_1] = \beta_1,\, \forall\beta_0,\beta_1}_{nedeplasare}. \]
Observăm că
\[ \mathbb{E}[\tilde\beta_1] = \beta_0\sum_{i = 1}^{n}d_i + \beta_1\sum_{i = 1}^{n}d_i x_i + \sum_{i = 1}^{n}d_i\underbrace{\mathbb{E}[\varepsilon_i]}_{=0} = \beta_0\sum_{i = 1}^{n}d_i + \beta_1\sum_{i = 1}^{n}d_i x_i \]
prin urmare, folosind proprietatea de nedeplasare, \(\beta_0\sum_{i = 1}^{n}d_i + \beta_1\sum_{i = 1}^{n}d_i x_i = \beta_1\) pentru orice valori ale lui \(\beta_0\) și \(\beta_1\) ceea ce implică \(\sum_{i = 1}^{n}d_i = 0\) și respectiv \(\sum_{i = 1}^{n}d_i x_i = 1\).
Pentru a verifica inegalitatea \(Var(\tilde\beta_1)\geq Var(\hat\beta_1)\), să notăm că
\[ Var(\tilde\beta_1) = Var(\tilde\beta_1 - \hat\beta_1) + Var(\hat\beta_1) + 2Cov(\tilde\beta_1 - \hat\beta_1, \hat\beta_1) \]
dar
\[ Cov(\tilde\beta_1 - \hat\beta_1, \hat\beta_1) = Cov(\tilde\beta_1, \hat\beta_1) - Var(\hat\beta_1) = \sigma^2\frac{\sum_{i = 1}^{n}d_i(x_i - \bar x)}{\sum_{i = 1}^{n}(x_i - \bar x)^2} - \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2} \]
și ținând cont că \(\sum_{i = 1}^{n}d_i = 0\) și \(\sum_{i = 1}^{n}d_i x_i = 1\) rezultă că \(Cov(\tilde\beta_1 - \hat\beta_1, \hat\beta_1) = 0\) ceea ce conduce la
\[ Var(\tilde\beta_1) = Var(\tilde\beta_1 - \hat\beta_1) + Var(\hat\beta_1) \geq Var(\hat\beta_1) \]
În modelul de regresie liniară simplă am estimat prin intermediul metodei celor mai mici pătrate atât ordonata la origine a dreptei de regresie, coeficientul \(\hat\beta_0\), cât și panta acesteia, coeficientul \(\hat\beta_1\). Definim valorile reziduale \(\hat\varepsilon_i\) ca fiind diferența dintre ordonata observată a punctului și ordonata ajustată la dreapta de regresie, altfel spus
\[ \hat{\varepsilon}_{i}=y_{i}-\hat{y}_{i}=y_{i}-\hat{\beta}_{0}-\hat{\beta}_{1} x_{i}. \]
Propoziția 2.5 (Suma valorilor reziduale nulă) În cadrul modelului de regresie liniară simplă, suma valorilor reziduale este nulă.
Demonstrație (Propoziția 2.5). Observăm, folosind definiția \(\hat\varepsilon_i = y_i - \hat y_i\), că
\[ \begin{aligned} \sum_{i = 1}^{n}\hat\varepsilon_i &= \sum_{i = 1}^{n}(y_i - \hat y_i) = \sum_{i = 1}^{n}(y_i - \hat \beta_0 - x_i\hat\beta_1)\\ &= \sum_{i = 1}^{n}\left[y_i - \underbrace{(\bar y - \bar x\hat\beta_1)}_{= \hat \beta_0} - x_i\hat\beta_1\right] = \sum_{i = 1}^{n}(y_i - \bar y) -\hat\beta_1 \sum_{i = 1}^{n}(x_i - \bar x) = 0. \end{aligned} \]
Trebuie observat că atât varianțele cât și covarianța estimatorilor \(\hat\beta_0\) și \(\hat\beta_1\) depind de varianța termenului eroare \(\sigma^2\), care în general nu este cunoscută. În propoziția de mai jos este propus un estimator nedeplasat a lui \(\sigma^2\).
Propoziția 2.6 (Estimator nedeplasat pentru \(\sigma^2\)) În modelul de regresie liniară simplă statistica \(\hat\sigma^2 = \frac{1}{n-2}\sum_{i = 1}^{n}\hat\varepsilon_i^2\) este un estimator nedeplasat pentru \(\sigma^2\).
Demonstrație (Propoziția 2.6). Ținând cont de faptul că \(\hat\beta_0 = \bar y - \hat\beta_1 \bar x\) și \(\bar y = \beta_0 + \beta_1 \bar x + \bar \varepsilon\) (prin însumarea după \(i\) a relațiilor \(y_i = \beta_0 + \beta_1 x_i +\varepsilon_i\)) găsim că
\[\begin{align*} \hat\varepsilon_i &= y_i - \hat y_i = (\beta_0 + \beta_1 x_i +\varepsilon_i) - (\hat\beta_0 + \hat\beta_1 x_i) \\ &= (\underbrace{\bar y - \beta_1 \bar x - \bar \varepsilon}_{=\beta_0} + \beta_1 x_i +\varepsilon_i) - (\bar y - \hat\beta_1 \bar x + \hat\beta_1 x_i)\\ &= (\beta_1 - \hat\beta_1)(x_i - \bar x) + (\varepsilon_i - \bar\varepsilon) \end{align*}\]și prin dezvoltarea binomului și utilizând relația \(\hat\beta_1 = \beta_1 + \frac{\sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\) găsim
\[\begin{align*} \sum_{i = 1}^{n}\hat\varepsilon_i^2 &= (\beta_1 - \hat\beta_1)^2\sum_{i = 1}^{n}(x_i - \bar x)^2 + \sum_{i = 1}^{n}(\varepsilon_i - \bar\varepsilon)^2 + 2(\beta_1 - \hat\beta_1)\sum_{i = 1}^{n}(x_i - \bar x)(\varepsilon_i - \bar\varepsilon)\\ &= (\beta_1 - \hat\beta_1)^2\sum_{i = 1}^{n}(x_i - \bar x)^2 + \sum_{i = 1}^{n}(\varepsilon_i - \bar\varepsilon)^2 + 2(\beta_1 - \hat\beta_1)\sum_{i = 1}^{n}(x_i - \bar x)\varepsilon_i \\ &- 2(\beta_1 - \hat\beta_1)\bar\varepsilon\sum_{i = 1}^{n}(x_i - \bar x)\\ &= (\beta_1 - \hat\beta_1)^2\sum_{i = 1}^{n}(x_i - \bar x)^2 + \sum_{i = 1}^{n}(\varepsilon_i - \bar\varepsilon)^2 - 2(\beta_1 - \hat\beta_1)^2\sum_{i = 1}^{n}(x_i - \bar x)^2\\ &=\sum_{i = 1}^{n}(\varepsilon_i - \bar\varepsilon)^2 - (\beta_1 - \hat\beta_1)^2\sum_{i = 1}^{n}(x_i - \bar x)^2. \end{align*}\]Luând media găsim că
\[ \mathbb{E}\left(\sum_{i = 1}^{n}\hat\varepsilon_i^2\right) = \mathbb{E}\left(\sum_{i = 1}^{n}(\varepsilon_i - \bar\varepsilon)^2\right) - \sum_{i = 1}^{n}(x_i - \bar x)^2 Var(\hat\beta_1) = (n-1)\sigma^2 - \sigma^2 = (n-1)\sigma^2 \]
unde am folosit că \(\mathbb{E}\left(\frac{1}{n-1}\sum_{i = 1}^{n}(\varepsilon_i - \bar\varepsilon)^2\right) = \sigma^2\) (deoarece \(Var(\varepsilon_i) = \sigma^2\)).
Concluzionăm că \(\hat\sigma^2 = \frac{1}{n-2}\sum_{i = 1}^{n}\hat\varepsilon_i^2\) este un estimator nedeplasat pentru \(\sigma^2\).
Exemplul 2.2 (Prețul chiriilor în Munchen) Observăm că pentru setul de date care face referire la prețul chiriilor în Munchen, găsim că valoarea estimatorului varianței termenului eroare este \(\hat\sigma^2 = \frac{1}{n-2}\sum_{i = 1}^{n}\hat\varepsilon_i^2 =\) 1.5241065^{4} iar matricea de varianță-covarianță a estimatorilor obținuți prin metoda celor mai mici pătrate este
\[ \begin{aligned} W &= \begin{pmatrix}Var(\hat \beta_0) & Cov(\hat \beta_0, \hat \beta_1)\\ Cov(\hat \beta_0, \hat \beta_1) & Var(\hat \beta_1)\end{pmatrix} = \begin{pmatrix}\frac{\sigma^2\sum_{i = 1}^{n}x_i^2}{n\sum_{i = 1}^{n}(x_i - \bar x)^2} & -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\\ -\frac{\sigma^2 \bar x}{\sum_{i = 1}^{n}(x_i - \bar x)^2} & \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\end{pmatrix}\\ &= \begin{pmatrix}208.29 & -2.96\\ -2.96 & 0.04\end{pmatrix}. \end{aligned} \]
Unul dintre scopurile modelului de regresie este acela de a face predicție, cu alte cuvinte de a prezice valoarea variabilei răspuns \(y\) în raport cu o nouă observație a variabilei explicative \(x\).
Propoziția 2.7 (Varianța răspunsului mediu prezis și a erorii de predicție) Fie \(x_{n+1}\) o nouă valoare pentru variabila explicativă și ne propunem să prezicem valoarea \(y_{n+1}\) conform modelului
\[ y_{n+1} = \beta_0 + \beta_1 x_{n+1} + \varepsilon_{n+1} \]
cu \(\mathbb{E}[\varepsilon_{n+1}] = 0\), \(Var(\varepsilon_{n+1}) = \sigma^2\) și \(Cov(\varepsilon_{n+1}, \varepsilon_i)=0\) pentru \(i = 1,\ldots,n\).
Atunci varianța răspunsului mediu prezis este
\[ Var(\hat y_{n+1}) = \sigma^2\left[\frac{1}{n} + \frac{(x_{n+1} - \bar x)^2}{\sum_{i=1}^{n}(x_i - \bar x)^2}\right], \]
iar eroarea de predicție \(\hat\varepsilon_{n+1}\) satisface \(\mathbb{E}[\hat\varepsilon_{n+1}] = 0\) și
\[ Var(\hat\varepsilon_{n+1}) = \sigma^2\left[1 + \frac{1}{n} + \frac{(x_{n+1} - \bar x)^2}{\sum_{i=1}^{n}(x_i - \bar x)^2}\right]. \]
Demonstrație (Propoziția 2.7). Cum \(\hat y_{n+1} = \hat\beta_0 + \hat\beta_1 x_{n+1}\) avem
\[ \begin{aligned} Var(\hat y_{n+1}) &= Var(\hat\beta_0 + \hat\beta_1 x_{n+1}) = Var(\hat\beta_0) + 2Cov(\hat\beta_0, \hat\beta_1 x_{n+1}) + x_{n+1}^2Var(\hat\beta_1)\\ &= \frac{\sigma^2\sum_{i = 1}^{n}x_i^2}{n\sum_{i = 1}^{n}(x_i - \bar x)^2} - 2\frac{\sigma^2 \bar x x_{n+1}}{\sum_{i = 1}^{n}(x_i - \bar x)^2} + \frac{\sigma^2x_{n+1}^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\\ &= \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\left[\frac{1}{n}\sum_{i = 1}^{n}x_i^2 - 2x_{n+1}\bar x + x_{n+1}^2\right]\\ &= \frac{\sigma^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\left[\frac{1}{n}\sum_{i = 1}^{n}(x_i -\bar x)^2 + \bar x^2 - 2x_{n+1}\bar x + x_{n+1}^2\right]\\ &= \sigma^2\left[\frac{1}{n} + \frac{(x_{n+1} - \bar x)^2}{\sum_{i=1}^{n}(x_i - \bar x)^2}\right]. \end{aligned} \]
Constatăm că atunci când \(x_{n+1}\) este departe de valoarea medie \(\bar x\) răspunsul mediu are o variabilitate mai mare.
Pentru a obține varianța erorii de predicție \(\hat\varepsilon_{n+1} = y_{n+1} - \hat y_{n+1}\) să observăm că \(y_{n+1}\) depinde doar de \(\varepsilon_{n+1}\) pe când \(\hat y_{n+1}\) depinde de \(\varepsilon_i\), \(i\in\{1,2,\ldots,n\}\). Din necorelarea erorilor deducem că
\[ \begin{aligned} Var(\hat\varepsilon_{n+1}) &= Var(y_{n+1} - \hat y_{n+1}) = Var(y_{n+1}) + Var(\hat y_{n+1}) \\ &= \sigma^2\left[1 + \frac{1}{n} + \frac{(x_{n+1} - \bar x)^2}{\sum_{i=1}^{n}(x_i - \bar x)^2}\right]. \end{aligned} \]
Exercițiul 3.1 (Greutatea taților și a fiilor) Tabelul de mai prezintă o serie de date privind greutatea taților și respectiv a fiului lor cel mare
\[ \begin{array}{lcccccccccccc} Tata: & 65 & 63 & 67 & 64 & 68 & 62 & 70 & 66 & 68 & 67 & 69 & 71\\ Fiu: & 68 & 66 & 68 & 65 & 69 & 66 & 68 & 65 & 71 & 67 & 68 & 70 \end{array} \]
Obținem următoarele rezultate numerice
\[ \sum_{i = 1}^{12}t_i = 800 \quad \sum_{i = 1}^{12}t_i^2 = 53418 \quad \sum_{i = 1}^{12}t_i f_i = 54107 \quad \sum_{i = 1}^{12}f_i = 811 \quad \sum_{i = 1}^{12}f_i^2 = 54849. \]
Determinați dreapta obținută prin metoda celor mai mici pătrate a greutății fiilor în funcie de greutatea taților.
Determinați dreapta obținută prin metoda celor mai mici pătrate a greutății taților în funcie de greutatea fiilor.
Arătați că produsul pantelor celor două drepte este egal cu pătratul coeficientului de corelație empirică dintre \(t_i\) și \(f_i\) (sau coeficientul de determinare).
Exercițiul 3.2 (Puntajele la un curs de formare) Douăsprezece persoane sunt înscrise la un curs de formare. La începutul cursului, acești cursanți susțin o probă A ce valorează 20 de puncte. La finalul cursului, susțin o probă B, de același nivel. Rezultatele sunt prezentate în următorul tabel:
\[ \begin{array}{lcccccccccccc} \text { Proba A } & 3 & 4 & 6 & 7 & 9 & 10 & 9 & 11 & 12 & 13 & 15 & 4 \\ \text { Proba B } & 8 & 9 & 10 & 13 & 15 & 14 & 13 & 16 & 13 & 19 & 6 & 19 \end{array} \]
Reprezentați norul de puncte pe un grafic. Determinați dreapta de regresie și calculați coeficientul de determinare. Comentați rezultatele.
Două persoane par să se distingă de restul. Eliminați-le și determinați din nou dreapta de regresie pe cele zece puncte rămase. Calculați coeficientul de determinare și comentați rezultatele.
Exercițiul 3.3 (Compararea estimatorilor) Considerăm modelul statistic următor
\[ y_i=\beta x_i+\varepsilon_i, \quad i=1, \cdots, n \]
unde termenii eroare \(\varepsilon_i\) verifică \(\mathbb{E}\left[\varepsilon_i\right]=0\) și \(\operatorname{Cov}\left(\varepsilon_i, \varepsilon_i\right)=\sigma^2 \delta_{i, j}\).
\[ \hat{\beta}=\frac{\sum_{i=1}^n x_i y_i}{\sum_{i=1}^n x_i^2} \]
\[ \beta^*=\frac{\sum_{i=1}^n y_i}{\sum_{i=1}^n x_i}. \]
Arătați că \(\hat{\beta}\) și \(\beta^*\) sunt estimatori nedeplasați pentru \(\beta\).
Plecând de la ingalitatea lui Cauchy-Schwarz: dacă \(u=\left[u_1, \ldots, u_n\right]^{\intercal}\) și \(v=\left[v_1, \ldots, v_n\right]^{\intercal}\) sunt doi vectori din \(\mathbb{R}^n\), atunci produsul lor scalar (în modul) este mai mic decât produsul normelor, cu alte cuvinte :
\[ |\langle u, v\rangle| \leq\|u\| \times\|v\| \Longleftrightarrow\left|\sum_{i=1}^n\right| u_i v_i \mid \leq \sqrt{\sum_{i=1}^n u_i^2} \times \sqrt{\sum_{i=1}^n v_i^2} \]
cu egalitate dacă și numai dacă vectorii \(u\) și \(v\) sunt coliniari. Arătați că \(\operatorname{Var}\left(\beta^*\right)>\operatorname{Var}(\hat{\beta})\) cu excepția cazului în care toți \(x_i\) sunt egali.
Exercițiul 3.4 (Regresie liniară simplă) Avem \(n\) puncte \(\left(x_{i}, y_{i}\right)_{1 \leq i \leq n}\) și știm că există o relație de forma: \(y_{i}=a x_{i}+b+\varepsilon_{i}\), unde erorile \(\varepsilon_{i}\) sunt variabile centrate, necorelate și cu aceeași varianță \(\sigma^ {2}\).